In this section, we will cover the basics of exploratory and descriptive analysis in R. We will learn how to conduct some of the most common descriptive statistics, such as mean, median, mode, standard deviation, and variance. We will also look at basic distribution plots, such as histograms and box plots, to visualize the data.
3.1 Mean, median, and mode
TipAt the end of this section, you will be able to:
Calculate the mean, median, and mode of a dataset
For this section we will use the album_sales dataset, which we have already loaded in some of the videos. Let’s start by loading the dataset and displaying the first few rows:
library(tidyverse)# Load the album_sales dataset. The location of the dataset will be different based on where you saved it on your computer.album_sales <-read.csv("Datasets/album_sales.csv")# Display the first few rows of the datasethead(album_sales)
The dataset contains 5 variables: Adverts, Sales, Airplay, Attract and Genre. We will focus on the Sales variable for this section.
# Calculate the mean of the Sales variablemean_sales <-mean(album_sales$Sales)mean_sales
[1] 193.2
Let’s break down the code above:
We used the mean() function to calculate the mean of the Sales variable in the album_sales dataset. To do this, we specified the dataset album_sales and the variable Sales using the $ operator.
The mean sales value is stored in the mean_sales variable.
Next, let’s calculate the median of the Sales variable:
# Calculate the median of the Sales variablemedian_sales <-median(album_sales$Sales)median_sales
[1] 200
The code above calculates the median of the Sales variable in the album_sales dataset. The median sales value is stored in the median_sales variable.
Finally, let’s calculate the mode of the Sales variable. Unfortunately, R does not have a built-in function to calculate the mode. However, we do this in the following way:
# Calculate the mode of the Sales variablealbum_sales$Sales %>%table()
We can see from the output that the mode of the Sales variable is 210, since that value appears most frequently in the dataset (13 times).
3.2 Standard deviation and variance
TipAt the end of this section, you will be able to:
Calculate the standard deviation
Calculate the variance
Calculate the range of a dataset
Calculate the interquartile range (IQR)
Next, let’s calculate the standard deviation and variance of the Sales variable in the album_sales dataset:
# Calculate the standard deviation of the Sales variablesd_sales <-sd(album_sales$Sales)sd_sales
[1] 80.69896
The code above calculates the standard deviation of the Sales variable in the album_sales dataset. The standard deviation value is stored in the sd_sales variable.
Next, let’s calculate the variance of the Sales variable:
# Calculate the variance of the Sales variablevar_sales <-var(album_sales$Sales)var_sales
[1] 6512.322
The code above calculates the variance of the Sales variable in the album_sales dataset. The variance value is stored in the var_sales variable.
3.3 Range and interquartile range
The range of a dataset is the difference between the maximum and minimum values. Let’s calculate the range of the Sales variable in the album_sales dataset:
# Calculate the range of the Sales variablerange_sales <-range(album_sales$Sales)range_sales
[1] 10 360
The code above calculates the range of the Sales variable in the album_sales dataset. The range of the sales values is stored in the range_sales variable.
The interquartile range (IQR) is the difference between the 75th percentile (Q3) and the 25th percentile (Q1) of a dataset. Let’s calculate the IQR of the Sales variable in the album_sales dataset:
# Calculate the interquartile range of the Sales variableIQR_sales <-IQR(album_sales$Sales)IQR_sales
[1] 112.5
The code above calculates the interquartile range (IQR) of the Sales variable in the album_sales dataset. The IQR value is stored in the IQR_sales variable.
3.4 Distribution plots
TipAt the end of this section, you will be able to:
Create a histogram to visualize the distribution of a dataset
Create a box plot to visualize the distribution of a dataset
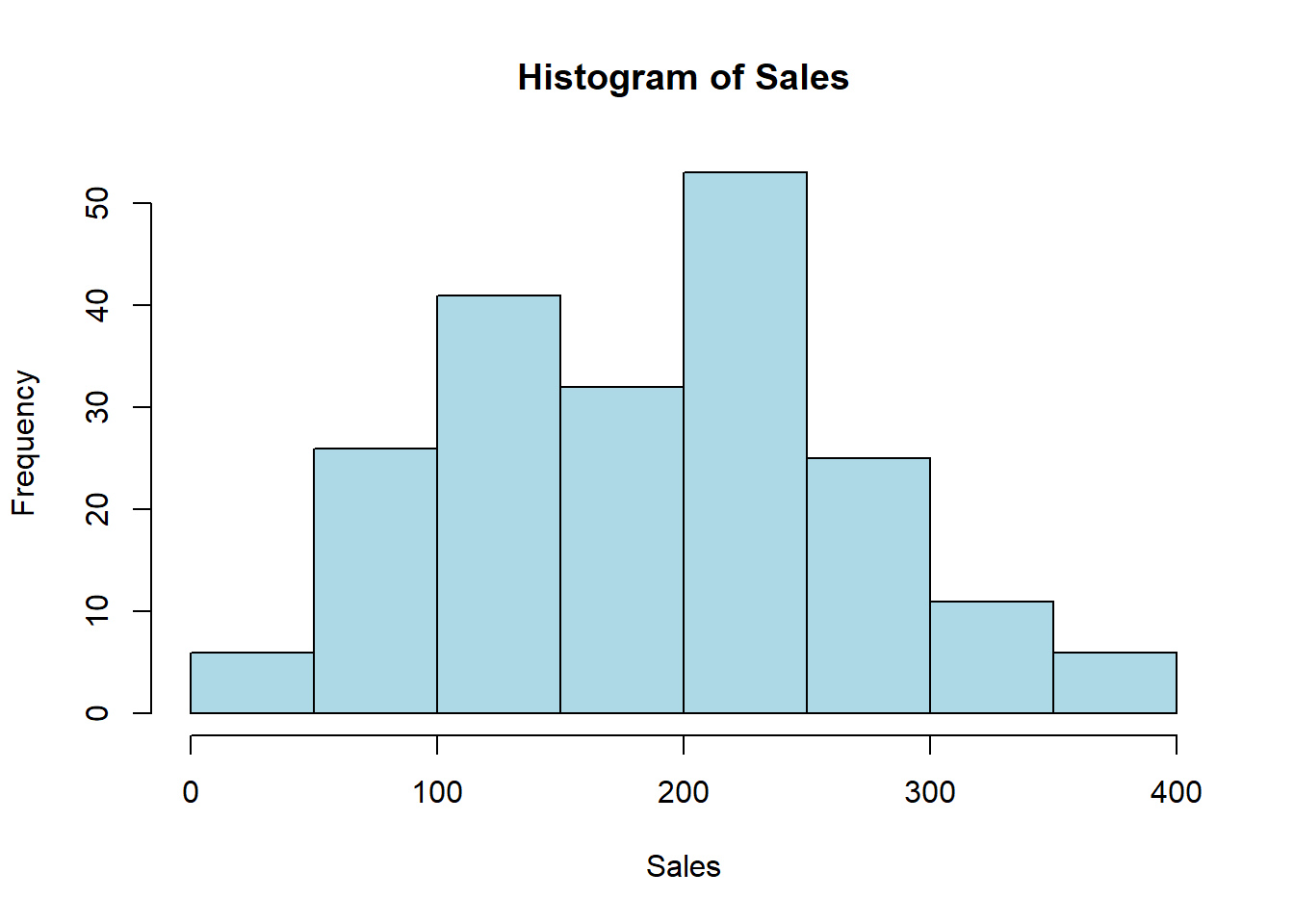
Next, let’s create a histogram to visualize the distribution of the Sales variable in the album_sales dataset:
# Create a histogram of the Sales variablehist(album_sales$Sales, main ="Histogram of Sales", xlab ="Sales", ylab ="Frequency", col ="lightblue")
The code above creates a histogram of the Sales variable in the album_sales dataset. The histogram displays the frequency of sales values in the dataset. The only required argument for the hist() function is the variable you want to plot. The main, xlab, ylab, and col arguments are optional and allow you to customize the appearance of the histogram.
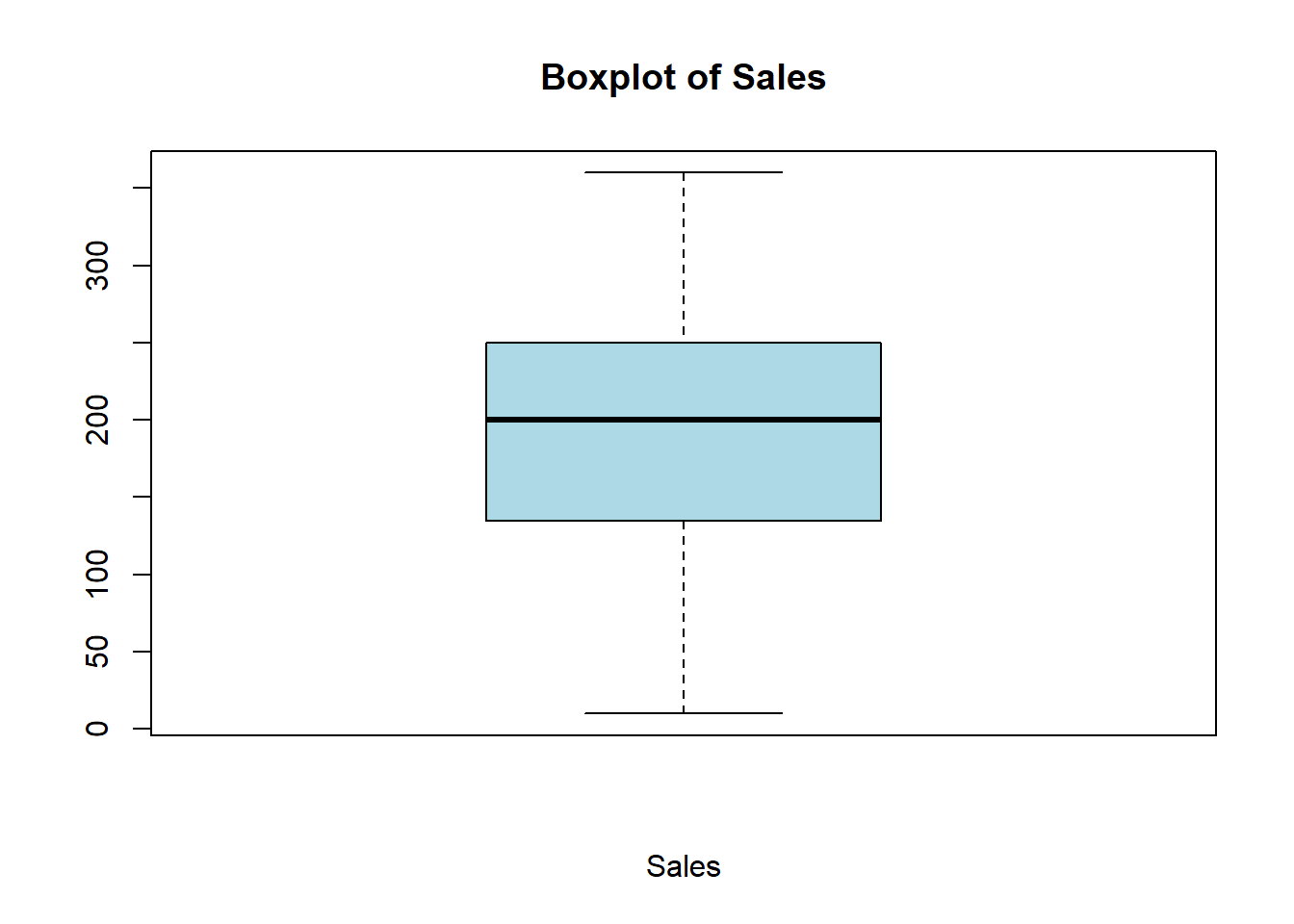
Finally, let’s create a box plot to visualize the distribution of the Sales variable in the album_sales dataset:
# Create a box plot of the Sales variableboxplot(album_sales$Sales, main ="Boxplot of Sales", xlab ="Sales", col ="lightblue")
The code above creates a box plot of the Sales variable in the album_sales dataset. The box plot displays the distribution of sales values, including the median, quartiles, and outliers. The only required argument for the boxplot() function is the variable you want to plot. The main, xlab, and col arguments are optional and allow you to customize the appearance of the box plot.
We will learn more about plotting data with ggplot2 in another section. However, for now, we have used the base R functions hist() and boxplot() to create simple distribution plots.
3.5 Assessing the normality of data
TipAt the end of this section, you will be able to:
Assess the skewness and kurtosis of a dataset
Test the normality of a dataset using the Shapiro-Wilk test
Many statistical tests assume that the data is normally distributed. When your data sample size is small, violation of the normaility assumption could be an issue. Let’s assess the normality of the Sales variable in the album_sales dataset by calculating the skewness and kurtosis. In order to do this, we will use the psych package, which provides functions for calculating skewness and kurtosis. If you haven’t installed the psych package yet, you can do so by running the following code:
# Install the psych package if you haven't alreadyinstall.packages("psych")
Now, let’s calculate the skewness and kurtosis of the Sales variable in the album_sales dataset:
# Load the psych packagelibrary(psych)
Attaching package: 'psych'
The following objects are masked from 'package:ggplot2':
%+%, alpha
# Calculate the skewness of the Sales variableskew_sales <-skew(album_sales$Sales)skew_sales
[1] 0.0432729
# Calculate the kurtosis of the Sales variablekurt_sales <-kurtosi(album_sales$Sales)kurt_sales
[1] -0.7157339
When interpreting the skewness and kurtosis values, remember that values of 0 indicate a normal distribution.
We can also test the normality of the Sales variable using the Shapiro-Wilk test. The null hypothesis of the Shapiro-Wilk test is that the data is normally distributed. Let’s perform the Shapiro-Wilk test on the Sales variable in the album_sales dataset:
# Perform the Shapiro-Wilk test on the Sales variableshapiro.test(album_sales$Sales)
Shapiro-Wilk normality test
data: album_sales$Sales
W = 0.98479, p-value = 0.02965
The output of the Shapiro-Wilk test includes the test statistic and the p-value. If the p-value is less than 0.05, we reject the null hypothesis and conclude that the data is not normally distributed. If the p-value is greater than 0.05, we fail to reject the null hypothesis and conclude that the data is normally distributed.
WarningAssessing normality
The shapiro-wilk test is sensitive to sample size. For small sample sizes, the test may be too conservative and reject the null hypothesis too often. For large sample sizes, the test may be too lenient and fail to reject the null hypothesis too often. Therefore, you should not rely solely on the Shapiro-Wilk test to assess the normality of your data. Visual inspection of the data using histograms and Q-Q plots is also recommended. Also remember that the central limit theorem states that the sampling distribution of the mean will be approximately normally distributed for large sample sizes, regardless of the distribution of the original data.
We could also use non-parametric bootstrapping methods to deal with non-normal data. We will cover this in a later section.